Architecture of an early stage SAAS

Design principles, tradeoffs and tricks used to build, deploy and run Feelback, an API-centric SAAS
Introduction
In this article I describe a simple architecture for an early stage SAAS. As a solo founder, I report some choices made to launch Feelback, a small-scale SAAS for collecting users signals about any content.
This article will cover the technical side of designing and running a simple SAAS. It will also include some details about coding and evolving the initial feature set ready at launch. However, research, marketing, administrative, financial and many other aspects required to run a business are not examined here.
Some questions you will find answers to:
- How to design a low-maintenance architecture?
- Which hosting and providers to choose and what configurations to use?
- How to deploy to production with ease?
- How to manage a monorepo with all service systems and components?
In case you landed here for the first time, to better understand the architecture and the choices made, here’s a brief introduction of Feelback and what services provides.
What is Feelback?
Feelback allows you to collect any kind of feedback on your websites or apps. You can receive several type of signals, for example:
Votes and Ratings



Feedback Forms

Likes and Reactions


Feelback integrates nicely with any website or tech, and provides many pre-configured components ready to be included in your pages with no effort.
You can read the following articles for use cases:
Architecture
Design principles
For the first stage of Feelback, I designed the architecture following three basic principles:
Simplicity
The least amount of moving parts. No fancy stuff, but old boring things that works. No complex setup to anticipate the next level scale.
Low maintenance
Smooth to deploy, painless to maintain, easy to monitor. Keep overheads and technical troubles at minimum.
Cost effective and (some-what) flexible
Adopt cloud resources and features when strictly needed, while having some degree of flexibility. It should accommodate temporary traffic spikes, without breaking down to pieces, if some kind of occasional surge happens.
Infrastructure
Feelback architecture is API-centric. It offers all service features though an API. In addition, the managing and configuration functionalities are exposed via the same API. As result the core API server involves almost all business logic, while the surrounding elements present or refine information to the user.
If we zoom-out, the overall Feelback architecture can be sliced in two parts: frontend and backend.
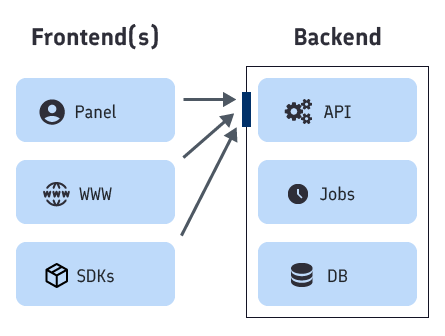
Although, both frontend and backend aren’t used in their strict meaning, this article misuses both terms in favor of a simpler mental model to follow.
Based more on a functional and responsibility separation:
Where inputs are received, where answers are given, where information and data are processed and stored. Here’s where all the logic runs. Where the dynamic part of the business dwells. It’s the complex side. It requires most of the design effort, where a bad decision or an overlooked issue can have long ramifications and will be costly to overcome.
Where information are presented, where inputs are generated, where questions are asked, where requests are sent from. Frontends don’t run any business logic. They are mostly static, generated or built in advance. Let’s call it the dumb side, where less design thinking is needed. Where bad decisions or breaking errors can easily recovered and patched up.
In conjunction, Feelback uses some external services, which can be placed in the same two-side layout, as request senders or request receivers.
On both sides, for each component, this article will explore three main topics:
Infrastructure
Which services and providers Feelback uses and how are connected
Configurations
What setup and configurations are in place while running
Deploy
How the code is built, packaged and sent to production environments
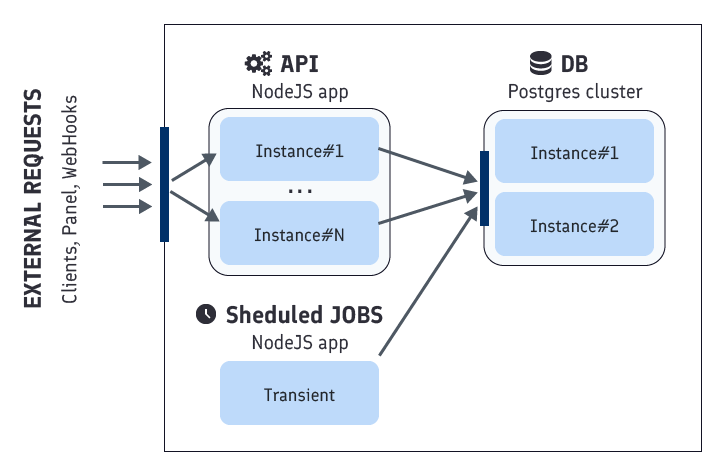
Backend
The Feelback backend is composed by 3 logical systems:
- API - exposes the Feelback service and features over HTTP
- Worker - executes scheduled jobs
- DB - postgres cluster for the data persistence
The entire backend is hosted on Fly. Lightweight virtual machines, called Fly Machines, lay the ground of the Fly infrastructure as a service. On top, the Fly App layer offers a simplified platform to coordinate, configure and deploy apps with little effort and almost no operations needed.
In the Feelback architecture, each system is mapped to a Fly App, abstracting over several underlying Machines with different scaling configurations.
Fly accepts container-based deploys. You can build standard container images with docker and push them to Fly. The deploy orchestrator will gracefully replace running machine instances with the new version.
In addition, Fly provides several features tailored for http servers. The Fly App automatically manages endpoint public ports, custom domains, SSL certificate handling and renewal, load balancing and many other technical things to get and keep the underlying app running.
These features drastically reduces the operations Feelback have to do in house, as infrastructure-wise everything is already handled. After the initial setup, all that is needed, is just to push a container with the new software version.
Although, Fly offers multi-region deployments, meaning you can spread machine instances over multiple physical locations, at launch Feelback architecture is deployed to a single region.
API
The Feelback API is the core system of the Feelback service. It fulfills three main purposes:
Feedback ingestion
Collects user feedbacks and signals from websites and apps where the Feelback service is integrated. In addition, clients can edit or remove a feedback if the configured time-window allows it.
Stats querying
Clients can get aggregate statistics for a content. For example the like count to show a counter on the UI. Or the overall sentiment to display the percentage split between up-votes and down-votes.
Project management
This the private part of the API, used to manage Feelback projects. The primary client is the Feelback Panel, the main dashboard where Feelback customers can create projects, organize contents and configurations.
The Feelback API is a NodeJS app. It’s built with httpc which allows to create APIs as function calls in an RPC-like fashion. Httpc generates a custom typed client to ensure end-to-end type safety with typescript powered clients.
Together with the whole Feelback backend, the Feelback API is hosted on Fly as a Fly App. A Fly App is an abstraction over several Fly Machines, that is, the actual VM CPU/RAM running them.
Configuration
The Feelback API uses a fly.toml file to set configurations and environment variables.
Fly Machines provide an easy way to configure an auto-scaling behavior for an app. The mechanism is based on usage thresholds. The Feelback API uses the following values:
[http_service]
[http_service.concurrency]
type = "requests"
soft_limit = 150
hard_limit = 200The Fly App proxy monitors the connections and, according to the thresholds set, can add new machines when more traffic is incoming. The same happens if, for a period of time, traffic is under threshold, excesses machines get shutdown.
This auto-scaling behavior is enabled by two flags:
[http_service]
auto_start_machines = true
auto_stop_machines = trueWith the previous configuration, the Fly proxy can automatically add and remove app instances and meet traffic demands.
Each app instance is a Fly Machine. We preallocated 4 Fly Machines for the API, as for the actual business size is more than enough to cover also surprise usage.
To prevent the auto-scaling process to completely shutdown the API, a minimum value of active running instances is set.
[http_service]
min_machines_running = 2This ensures some sort of in-region redundancy. If an instance crashes or gets stuck, the service is up nonetheless, with the other instance fulfilling requests. In the meantime, the auto-scaler will kill the bad instance and starts a new one.
Deploy
Fly allows to deploy apps by simply uploading a container image. A Github Action workflows build the Feelback API image with Docker on each push to master. Then, an action sends the image to Fly.
The workflow uses the superfly/flyctl-actions to deploy the image.
jobs:
deploy:
# ... build steps
- name: Deploy to Fly
uses: superfly/[email protected]
env:
FLY_API_TOKEN: ${{ secrets.FLY_AUTH_TOKEN }}
with:
args: "deploy ./packages/api/ --local-only --image feelback_api:latest"The Feelback API is a simple NodeJS with no special prerequisite. The container image is based on Alpine, a lightweight linux-based distribution ready for NodeJS.
The container image is created by Docker with a two-stage build. The first stage installs all dev dependencies and builds the sources. The second stage install production-only dependencies and copies first-stage outputs to the final image.
For reference, here’s the complete dockerfile:
#
# Stage 1: Build from dev
#
FROM node:18-alpine
RUN npm install -g [email protected]
WORKDIR /app
COPY package.json .
COPY pnpm-*.yaml .
COPY patches/ patches
RUN pnpm fetch --ignore-scripts
COPY packages/api/package.json packages/api/
RUN pnpm install --offline --frozen-lockfile
COPY tsconfig* .
COPY packages/api/tsconfig* packages/api/
COPY packages/api/src/ packages/api/src
RUN pnpm run --filter @feelback/api generate:prisma
RUN pnpm run --filter @feelback/api build
#
# Stage 2: final build no dev
#
FROM node:18-alpine
ENV NODE_ENV=production
RUN npm install -g [email protected]
WORKDIR /app
COPY --from=0 /app/package.json .
COPY --from=0 /app/pnpm-*.yaml .
COPY --from=0 /app/patches/ patches
COPY --from=0 /app/packages/api/package.json packages/api/
RUN pnpm install --frozen-lockfile --prod
COPY packages/api/src/data/ packages/api/src/data/
COPY --from=0 /app/packages/api/dist/ packages/api/dist
WORKDIR /app/packages/api
EXPOSE 3000
ENTRYPOINT [ "pnpm", "start" ]Scheduled jobs worker
The worker executes periodic jobs. There’re three main jobs run:
Feedback stats aggregation
For each content and content-set, Feelback provides weekly, monthly, yearly and various rolling-window aggregates. Aggregate values depends on the feelback-type associated with the content. For example, the like count as the total number of likes received for a specified content. Other aggregates involve sentiment, average and compound calculations.
Aggregates are calculated daily and stored in the DB. A single fast query can pickup the preprocessed data with efficient performance without wasting CPU cycles.
Weekly/Monthly recaps
Customers can subscribe to a period report to be delivered via mail. Overall performance are summarized weekly and monthly. For each project, the worker calculates content performance for the period, composes a mail with nice graphs and stat counters and send it.
Recaps are scheduled the first of each month, covering the previous month data. And every Monday, for the previous week.
Data cleanup
A job scheduled weekly to run some data clean. Expired data, such as temporary access tokens and partial aggregates, is deleted form the DB. Other transient artifacts are removed.
Configuration
In the Feelback architecture there’s no queue nor bus. The Worker just executes scheduled jobs. Therefore the Worker doesn’t run continuously, instead it gets started whenever the scheduled times approach.
A Fly machine is pre-created for the Worker. The machine is always stopped.
At the moment, Fly doesn’t have a global scheduler or a way to run machines on demand via configuration. So a simple manual call to the Fly Machine API is made to start the Worker.
When the API app starts, it runs a little in-process scheduler which performs the wake up call. Each day the API app calls the Fly Machine API to start the Worker with a simple function.
async function startWorker() {
const machineId = process.evn.FLY_WORKER_MACHINE_ID;
const authToken = process.evn.FLY_API_TOKEN;
const response = await fetch(`https://_api.internal:4280/v1/apps/user-functions/machines/${machineId}/start`, {
method: "POST",
headers: {
authorization: `Bearer ${authToken}`,
"content-type": "application/json"
}
});
return await response.json();
}After the processing is done, Fly automatically shuts down and stops the worker machine as the main process naturally exits.
To avoid multiple starts, a quick check to the DB is made. A single record tracks the last worker run with a startedAt column. Before the call, the record is locked for update and tested for the today date. After the call, the record is updated with today’s date and released.
Deploy
The Worker is just a small util around business logic already provided by the API. Hence, it shares 99% of code with the API.
For the sake of making things simple, the Worker is packaged within the API. The API container image contains also the Worker bootstrap code. This allows to deploy just a single container image for both the API and the Worker.
On each push on master, a Github Action workflows build the image and sends it to Fly. An environment variable is set for the Worker Machine. So, on launch, the code understands it’s in Worker mode and runs the scheduler, instead of starting the API server.
DB cluster
You should always start with Postgres
Secret guide to speedrun-launch a SAAS, 2nd chapter
The Feelback uses a Postgres DB as its main persistence system. The DB is hosted on Fly, in the same region of the API app. Fly offers a first-party solution for a Postgres cluster with flexible scaling features.
The Fly Postgres allows us to have an hands-on solution with no much trouble nor thinking, as the setup and monitoring a DB is hard. In addition, we can easily scale both for CPU power and data storage, as the business increases.
The Feelback DB is configured as 2-node cluster using stolon to manage the nodes for leader election and replica. On top, stolon provides a proxy the API can talk to that routes connections to the right Postgres node. All this configuration is preset by Fly. So everything comes out-of-the box when we created the cluster.
The postgres DB is exposed as a single private endpoint inside the internal network. Fly automatically provides an environment variable DATABASE_URL the API app uses to establish the right connection.
Backup
Fly performs daily snapshot of postgres volumes. Snapshots can be restored at any time, thus a first-line backup solution is already in place out the box. At the time of writing, snapshots persists for 5 days.
An additional backup is executed outside Fly, via an AWS lambda. A scheduled function connects to the Feelback DB and dumps the entire db to an S3 bucket.
For now, we don’t delete DB backups, we keep backups on S3 indefinitely. In future as the business increases in size, we’ll set a consolidation policy in place.
Frontend(s)
The Feelback frontends include:
- User Panel - main access point where a user manage Feelback projects
- Home & Docs website - the public presence of the Feelback service
- SDKs - client libraries used to integrate Feelback with any website
Both websites are static websites and are hosted on Cloudflare.
SDKs are client libraries Feelback users can adopt to easily integrate Feelback to their websites and start collecting feedbacks. SDKs target different frameworks like React, Astro, vanilla Javascript, Vue, etc…
User Panel
The User Panel is the preferred way to access the Feelback service. A user can create and manage Feelback projects. He can see feedback aggregated stats and checkout content performance. He can analyze every single feedback and manage data exports.
The User Panel is a plain React SPA. No meta-framework is used. The app is bundled with vite via esbuild to just static assets. The JS bundle is split in several parts which are dynamically loaded when needed.
The User Panel is totally static and distributed by Cloudflare Pages. Through the Cloudflare CDN the User Panel app is served with fast performance, as static assets are delivered by servers close to the user.
The User Panel performs no business logic. All Feelback functionalities are achieved connecting to the Feelback API. The User Panel uses the API client generated by httpc to stay up-to-date with the Feelback API type definitions and, thus, achieving end-to-end type-safety.
Deploy
The User Panel deployment consists only in building the static assets and pushing them to Cloudflare. A GitHub Action workflow runs on every push to master. The workflow builds the website and send the output to Cloudflare via wrangler, a CLI tool developed by Cloudflare to easily interact with its services.
For reference, the complete workflow file:
name: deploy_panel
on:
push:
branches: [master]
paths: ["packages/panel/**"]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup node & pnpm
uses: ./.github/actions/setup-env
- name: Test
run: pnpm run --filter @feelback/panel test
- name: Build
run: pnpm run --filter @feelback/panel build
env:
VITE_API_ENDPOINT: https://api.feelback.dev/v0
- name: Deploy
run: pnpm run --filter @feelback/panel deploy
env:
CLOUDFLARE_ACCOUNT_ID: ${{ secrets.CLOUDFLARE_ACCOUNT_ID }}
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_AUTH_TOKEN }}While the package scripts are:
{
"scripts": {
"build": "tsc && vite build",
"deploy": "wrangler pages publish dist --project-name feelback-panel --branch main",
"test": "jest",
}
}Home & Docs website
The main website www.feelback.dev. The website includes the marketing and landing pages, the documentation and the blog.
The website is build with Astro and is completely generated at build time, making it a 100% static website with no server-side components. Some pages with interactivity loads preact on-demand to provide client interactions. Astro integrate natively with frameworks like preact, making the effort just a line of configuration.
Similar to the User Panel, the Home website is completely static and hosted on Cloudflare Pages.
Deploy
The deployment process of the Home website is the same of the User Panel. On each push to master, a GitHub Action workflow builds the website and sends it to Cloudflare.
The complete workflow file:
name: deploy_www
on:
push:
branches: [master]
paths: ["packages/www/**"]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup node & pnpm
uses: ./.github/actions/setup-env
- name: Build
run: pnpm run --filter @feelback/www build
- name: Deploy
run: pnpm run --filter @feelback/www deploy
env:
CLOUDFLARE_ACCOUNT_ID: ${{ secrets.CLOUDFLARE_ACCOUNT_ID }}
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_AUTH_TOKEN }}And the package scripts are:
{
"scripts": {
"build": "astro build",
"deploy": "wrangler pages publish dist --project-name feelback-www --branch main"
}
}SDKs
Feelback offers first-party client packages to quickly integrate Feelback with any website. Feelback supports any technology. From static site generators to SPA frameworks like React or Vue, from site builder like Wordpress to plain HTML/Javascript.
Different SDKs are developed to target the major frameworks and libraries.
Feelback SDKs are open-source and developed on a public Github repository. Each SDK package is published to npm under the @feedback scope.
Websites using any Feelback SDKs interact with the Feelback service via the API. Thus, making them clients of the service.
External services
As described in the Architecture chapter, the Feelback architecture relies on two essential service providers:
- Fly - for all backend production infrastructure
- Cloudflare - for all frontend hosting
In addition, Feelback depends on several auxillary providers:
Billing, invoicing and subscription management for paid plans. The Feelback API and the Job processor interact with Stripe API for both realtime operations, like a change plan, and for background process like updating invoices and customer data. In addition, the Feelback API receives and processed the Stripe Webhook requests, mostly for notifications about subscription events.
Feelback uses MailerSend as email provider for both notification emails such as login requests and password management, and for reporting emails like weekly recaps.
Backend info and error logs are streamed to Logflare which ingests log entries as JSON. We use a custom HTTP Transport for winston, our logging library of choice. Logs are batched and sent to the Logflare API, enriched with basic metadata like request identifiers and relevant environment variables.
For client side, aka frontends, error monitoring.
A self-hosted instance of Metabase is used for internal dashboards and business goal tracking.
AWS for Backup
AWS is used to make backups of the database. A scheduled lambda runs at specified intervals, and backups the whole db to an S3 bucket.
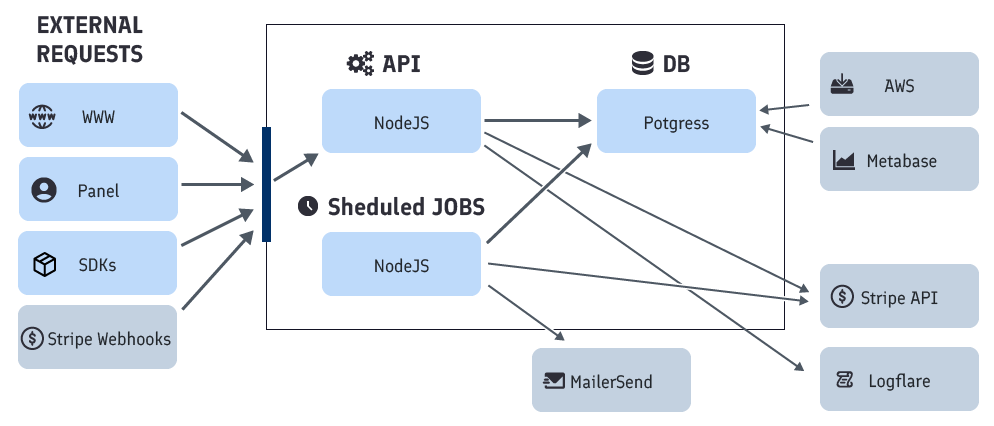
The overall architecture diagram of the Feelback SAAS is something like:
Conclusions
Building a SAAS, aka the product, is quite easy compared to building the business to sustain it. Unless you’re on a cutting-edge crazy research project, developing the service is the easiest part. Aside technical skills, bootstrapping a SAAS from zero requires mental effort the most. The mental energy to keep pushing in a somewhat adverse environment.
To reduce the mental weight, every solution, choice or trick discussed here, were made pursing simplicity and avoid any complication. Keep things extremely simple. Don’t charge any toll on the mind about technical unproductive matters. Nor design things to handle a supposed next-stage scale.
Hope the info I wrote here can be useful to those who are in the same boat as me, rowing and pushing in these unresting waters. Or, maybe, inspire to begin a new journey.
Additional resources
If you curious about Feelback and what offers:
- See the getting started guide with an overview of the Feelback service and all the features available
- Checkout the tutorials to see how you can integrate Feelback with any website and start collecting feedbacks